選擇我們最好的考試認證資料DY0-001題庫資料: CompTIA DataAI Certification Exam,復習準備CompTIA DY0-001很輕松
Wiki Article
從Google Drive中免費下載最新的NewDumps DY0-001 PDF版考試題庫:https://drive.google.com/open?id=1XtmEkH8CIXrBi7BOHQh-Ft_SbiTDIVi1
獲得 CompTIA CompTIA 認證對於考生而言有很多好處,相對于考生尋找工作而言,一張 CompTIA 的 DY0-001 認證會讓你倍受青睞的企業信任狀,帶來更好的工作機會。要想通過此認證學習過程中要注意方法,最重要的是需要毅力,如果有相關的工作經驗,學起來可能輕鬆一點,否則的話,你需要付出更多的勞動。CompTIA 的 DY0-001 證照作為全球IT領域專家 CompTIA 證照之一,是許多大中IT企業選擇人才標準的必備條件。
CompTIA 的 DY0-001 考古題是從Prometric或VUE考試中心取得的最新原始考題,由資深講師和技術專家精心打造的完美產品,保證了 DY0-001 產品的高品質和真實性。已經幫助很多考生成功通過考試,擁有了NewDumps DY0-001 考題您就可以實現理想,適合全球考生都能通用的模擬試題。因為最新的 DY0-001 擬真試題可以為你的複習和看書減輕很多的煩惱。
DY0-001考試備考經驗 - DY0-001題庫下載
與 NewDumps考古題的超低價格相反,NewDumps提供的DY0-001考試考古題擁有最好的品質。而且更重要的是,NewDumps為你提供優質的服務。只要你支付了你想要的考古題,那麼你馬上就可以得到它。NewDumps網站有你最需要的,也是最適合你的考試資料。你購買了DY0-001考古題以後還可以得到一年的免費更新服務,一年之內,只要你想更新你擁有的資料,那麼你就可以得到最新版。NewDumps盡最大努力給你提供最大的方便。
CompTIA DY0-001 考試大綱:
| 主題 | 簡介 |
|---|---|
| 主題 1 |
|
| 主題 2 |
|
| 主題 3 |
|
| 主題 4 |
|
| 主題 5 |
|
最新的 CompTIA Data+ DY0-001 免費考試真題 (Q51-Q56):
問題 #51
Which of the following JOINS would generate the largest amount of data?
- A. INNER JOIN
- B. CROSS JOIN
- C. RIGHT JOIN
- D. LEFT JOIN
答案:B
解題說明:
# A CROSS JOIN returns the Cartesian product of the two tables - meaning every row from the first table is paired with every row from the second table. If Table A has m rows and Table B has n rows, a CROSS JOIN will return m × n rows, making it the largest possible result set of all JOIN types.
Why the other options are incorrect:
* A & B: RIGHT JOIN and LEFT JOIN return matched records plus unmatched rows from one side - but not all possible combinations.
* D: INNER JOIN returns only matched rows between tables, typically producing fewer records than a CROSS JOIN.
Official References:
* CompTIA DataX (DY0-001) Official Study Guide - Section 5.2:"CROSS JOINs generate the Cartesian product of two datasets and should be used carefully due to the exponential growth in the number of records."
* SQL for Data Scientists, Chapter 3:"CROSS JOINs can produce very large datasets, often unintentionally, due to their non-restrictive matching logic."
-
問題 #52
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R² of 0.75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?
- A. The model should be deployed because it has a lower RMSE.
- B. The model's adjusted R² is too low for the real estate industry.
- C. The model fails to improve meaningfully on the benchmark model.
- D. The model's adjusted R² is exceptionally strong for such a complex relationship.
答案:C
解題說明:
# The difference between the benchmark RMSE (1,000) and the new model RMSE (995) is minimal and may not justify replacing the existing model. Though the adjusted R² is decent, business decisions should be based on whether the improvement is statistically and practically significant.
Why the other options are incorrect:
* A: The RMSE improvement is marginal and may not be worth deployment effort.
* B: The adjusted R² of 0.75 is moderate, not necessarily "exceptionally strong."
* D: The claim about industry standards is unsupported and not universally true.
Official References:
* CompTIA DataX (DY0-001) Study Guide - Section 3.2:"Model selection must consider both statistical improvement and practical significance."
* Data Science Best Practices, Chapter 8:"Small improvements in performance metrics must be evaluated in the context of deployment cost and business impact."
-
問題 #53
The following graphic shows the results of an unsupervised, machine-learning clustering model: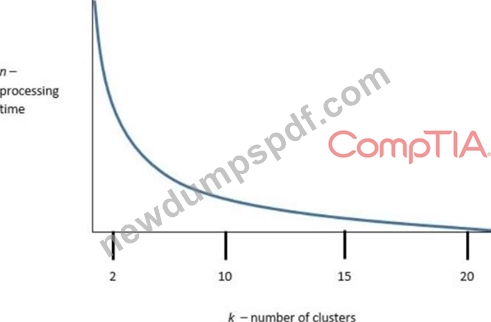
k is the number of clusters, and n is the processing time required to run the model. Which of the following is the best value of k to optimize both accuracy and processing requirements?
- A. 0
- B. 1
- C. 2
- D. 3
答案:D
解題說明:
# The graph represents a classic "elbow curve," which is often used in clustering (e.g., k-means) to help determine the optimal number of clusters. The point where the curve starts to level off (the "elbow") reflects the best trade-off between model accuracy and processing efficiency.
In this graph, the elbow visually occurs around k = 10. Beyond that, the processing time continues to decrease, but the marginal gain in clustering quality (or drop in processing time) diminishes.
Why the other options are incorrect:
* A: k = 2 underfits the data - too few clusters.
* C & D: k = 15 or 20 provides minimal additional benefit in processing but may overcomplicate the model.
Official References:
* CompTIA DataX (DY0-001) Study Guide - Section 4.2:"The elbow method identifies the optimal number of clusters where the rate of improvement drops significantly."
-
問題 #54
A movie production company would like to find the actors appearing in its top movies using data from the tables below. The resulting data must show all movies in Table 1, enriched with actors listed in Table 2.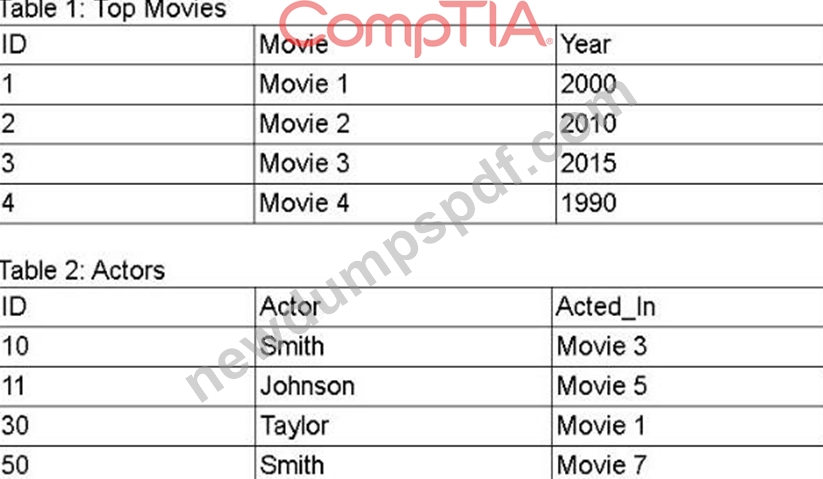
Which of the following query operations achieves the desired data set?
- A. Perform an INTERSECT between Table 1 using column Movie, and Table 2 using column Acted_In.
- B. Perform a LEFT JOIN on Table 1 using column Movie, with Table 2 using column Acted_In.
- C. Perform a UNION between Table 1 using column Movie, and Table 2 using column Acted_In.
- D. Perform an INNER JOIN between Table 1 using column Movie, and Table 2 using column Acted_In.
答案:B
解題說明:
A LEFT JOIN returns every row from Table 1 (all top movies) and brings in matching actors from Table 2 where the Movie = Acted_In, leaving NULLs for movies without listed actors.
問題 #55
A statistician notices gaps in data associated with age-related illnesses and wants to further aggregate these observations. Which of the following is the best technique to achieve this goal?
- A. Linearization
- B. Binning
- C. Imputing
- D. Label encoding
答案:B
解題說明:
Binning groups continuous age values into discrete intervals (e.g., age ranges), filling gaps by aggregating observations into broader categories. This directly addresses uneven or sparse age data by creating consistent age groups.
問題 #56
......
我們都清楚的知道,IT行業是個新型產業,它是帶動經濟發展的鏈條之一,所以它的地位也是舉足輕重不可忽視的。IT認證又是IT行業裏競爭的手段之一,通過了認證你的各方面將會得到很好的上升,但是想要通過並非易事,所以建議你利用一下培訓工具,如果要選擇通過這項認證的培訓資源,NewDumps CompTIA的DY0-001考試培訓資料當仁不讓,它的成功率高達100%,能夠保證你通過考試。
DY0-001考試備考經驗: https://www.newdumpspdf.com/DY0-001-exam-new-dumps.html
- DY0-001考試證照 ???? DY0-001 PDF ???? DY0-001熱門證照 ???? 立即在▶ tw.fast2test.com ◀上搜尋➡ DY0-001 ️⬅️並免費下載DY0-001認證考試解析
- DY0-001權威認證 ???? DY0-001認證考試解析 ???? DY0-001最新題庫資源 ???? 來自網站“ www.newdumpspdf.com ”打開並搜索《 DY0-001 》免費下載DY0-001软件版
- DY0-001软件版 ???? 新版DY0-001考古題 ???? DY0-001软件版 ???? ☀ www.pdfexamdumps.com ️☀️最新《 DY0-001 》問題集合DY0-001熱門題庫
- 最好的DY0-001題庫資料 |高通過率的考試材料|值得信賴的DY0-001考試備考經驗 ???? 打開☀ www.newdumpspdf.com ️☀️搜尋➤ DY0-001 ⮘以免費下載考試資料DY0-001考試題庫
- 有效的CompTIA DY0-001題庫資料&專業的www.newdumpspdf.com - 認證考試材料的領導者 ???? 透過➠ www.newdumpspdf.com ????搜索{ DY0-001 }免費下載考試資料DY0-001測試
- DY0-001最新題庫資源 ⬇ 最新DY0-001考古題 ???? 最新DY0-001考古題 ⏲ ☀ www.newdumpspdf.com ️☀️上的➠ DY0-001 ????免費下載只需搜尋DY0-001考試
- DY0-001最新考古題 ???? DY0-001考試題庫 ???? DY0-001 PDF ???? 立即打開☀ www.newdumpspdf.com ️☀️並搜索《 DY0-001 》以獲取免費下載DY0-001在線考題
- DY0-001软件版 ⏪ DY0-001權威認證 ???? DY0-001考試 ???? 立即打開➤ www.newdumpspdf.com ⮘並搜索☀ DY0-001 ️☀️以獲取免費下載DY0-001熱門證照
- DY0-001題庫分享 ???? DY0-001考試 ???? DY0-001考試題庫 ???? 在➡ www.testpdf.net ️⬅️上搜索⏩ DY0-001 ⏪並獲取免費下載DY0-001考題
- 值得信賴的DY0-001題庫資料&保證CompTIA DY0-001考試成功 - 準確的DY0-001考試備考經驗 ???? 透過“ www.newdumpspdf.com ”搜索➤ DY0-001 ⮘免費下載考試資料DY0-001最新題庫資源
- DY0-001熱門證照 ???? 最新DY0-001考古題 ???? DY0-001考試證照 ???? 開啟( tw.fast2test.com )輸入➠ DY0-001 ????並獲取免費下載DY0-001软件版
- saulaowa660144.dreamyblogs.com, ilovebookmark.com, pennykwct238296.wikiannouncement.com, www.prodesigns.com, aliviaziyc516321.wikilinksnews.com, optimusbookmarks.com, ihannamgut871594.aboutyoublog.com, brontediud872411.p2blogs.com, eternalbookmarks.com, zaynabhxgi866000.ttblogs.com, Disposable vapes
順便提一下,可以從雲存儲中下載NewDumps DY0-001考試題庫的完整版:https://drive.google.com/open?id=1XtmEkH8CIXrBi7BOHQh-Ft_SbiTDIVi1
Report this wiki page